OSMNX & Cenpy#
Using contextily to map OpenStreetMap & US Census bureau data#
In this notebook, we’ll discuss how to access open data sources, such as data from OpenStreetMap or the United States Census, and make static maps showing urban demographics and streets with basemaps provided by contextily. The three main packages covered in this notebook are explained below:
OSMNX#
OSMNX, (styled osmnx, pronounced as oh-ess-em-en-echs), is a well-used package to examine Open Streetmap data from python. A good overview of the core concepts & ideas comes from @gboeing, the lead author and maintainer of the package. Here, we’ll use it to extract the street network of Austin, TX.
Contextily#
Contextily (pronounced context-a-lee) is a python package that works with online map tile servers to provide basemaps for matplotlib plots. A ton of information on the package is available at `contextily.readthedocs.io <https://contextily.readthedocs.io/en/latest/>`__.
Cenpy#
CenPy (pronounced sen-pie) is a a python package for interacting with the US Census Bureau’s Data Products, hosted at `api.census.gov <https://api.census.gov>`__. The Census exposes a ton of data products for people to use. Cenpy itself provides 2 “levels” of access.
Census products#
Most users simply want to get into the census, retrieve data, and then map, plot, analyze, or model that data. For this, cenpy wraps the main “products” that users may want to access: the American Community Survey & 2010 Decennial Census. These are designed to interface directly with the US Census Bureau’s data APIs, get both the geographies & data from the US Census, and return that to the user, ready to plot. We’ll cover this API here.
Building Blocks of cenpy.products#
For those interested, cenpy also has a lower-level interface designed to directly interact with US Census data products through their two constituent parts: the data product from https://api.census.gov, and the geography product, from the US Census’s ESRI MapServer. This is intended for developers to build new products or to interface directly with the API as they wish. This is pretty straightforward to use, but requires a bit more technical knowledge to make just work, so if you
simply need US Census or ACS data, focus on the product API.
Using the Packages#
To use packages in python, you must first import the package. Below, we import three packages:
cenpyosmnxcontextilymatplotlib.pyplot
[1]:
import cenpy
import osmnx
import contextily
import matplotlib.pyplot as plt
%matplotlib inline
/opt/anaconda3/envs/analysis/lib/python3.8/site-packages/fuzzywuzzy/fuzz.py:11: UserWarning: Using slow pure-python SequenceMatcher. Install python-Levenshtein to remove this warning
warnings.warn('Using slow pure-python SequenceMatcher. Install python-Levenshtein to remove this warning')
osmnx, contextily, and cenpy.products work using a place-oriented API. This means that users specify a place name, like Columbus, OH or Kansas City, MO-KS, or California, and the package parses this name and grabs the relevant data. osmnx uses the Open Street Map service, cenpy uses the Us Census Bureau’s service, and contextily has its own distinctive set of providers so they can
sometimes disagree slightly, especially when considering older census products.
Regardless, to grab the US census data using cenpy, you pass the place name and the columns of the Census product you wish to extract. Below, we’ll grab two columns from the American Community Survey: Total population (B02001_001E) and count of African American persons (B02001_003E). We’ll grab this from Austin, TX:
[2]:
aus_data = cenpy.products.ACS().from_place('Austin, TX',
variables=['B02001_001E', 'B02001_003E'])
/opt/anaconda3/envs/analysis/lib/python3.8/site-packages/cenpy/geoparser.py:214: UserWarning: Shape is invalid:
Ring Self-intersection[-10884881.1468 3554135.7868]
tell_user('Shape is invalid: \n{}'.format(vexplain))
/opt/anaconda3/envs/analysis/lib/python3.8/site-packages/pyproj/crs/crs.py:55: FutureWarning: '+init=<authority>:<code>' syntax is deprecated. '<authority>:<code>' is the preferred initialization method. When making the change, be mindful of axis order changes: https://pyproj4.github.io/pyproj/stable/gotchas.html#axis-order-changes-in-proj-6
return _prepare_from_string(" ".join(pjargs))
Matched: Austin, TX to Austin city within layer Incorporated Places
/opt/anaconda3/envs/analysis/lib/python3.8/site-packages/pyproj/crs/crs.py:55: FutureWarning: '+init=<authority>:<code>' syntax is deprecated. '<authority>:<code>' is the preferred initialization method. When making the change, be mindful of axis order changes: https://pyproj4.github.io/pyproj/stable/gotchas.html#axis-order-changes-in-proj-6
return _prepare_from_string(" ".join(pjargs))
When this runs, cenpy does a few things:
it asks the census for all the relevant US Census Tracts that fall within Austin, TX
it parses the shapes of Census tracts to make sure they’re valid
it parses the data from the Census to ensure it’s valid
Above, you may see a warning that the Austin, TX shape is invalid! This is cenpy running validation on the data. This problem can be fixed, but does not immediately affect analyses.
Likewise, OSMNX has a place-oriented API. To grab the street network from Austin, we can run a similar query:
[3]:
aus_graph = osmnx.graph_from_place('Austin, TX')
However, the two pcakages default representations are quite different. osmnx focuses on the networkx package for its core representation (hence, osm for Open Streetmap and nx for NetworkX):
[4]:
aus_graph
[4]:
<networkx.classes.multidigraph.MultiDiGraph at 0x162e26b50>
In contrast cenpy uses pandas (and, specifically, geopandas) to express the demographics and geography of US Census data. These packages provide dataframes, like spreadsheets, which can be used to analyze data in Python. Below, each road contains the shape of one US Census tract (the geometry used by default in by cenpy), and the columns provide descriptive information about the tract.
[5]:
aus_data.head()
[5]:
| GEOID | geometry | B02001_001E | B02001_003E | state | county | tract | |
|---|---|---|---|---|---|---|---|
| 0 | 48453001777 | POLYGON ((-10893854.050 3530337.870, -10893733... | 6270.0 | 305.0 | 48 | 453 | 001777 |
| 1 | 48453001303 | POLYGON ((-10884014.410 3536874.560, -10883958... | 4029.0 | 41.0 | 48 | 453 | 001303 |
| 2 | 48453000603 | POLYGON ((-10881841.790 3540726.020, -10881828... | 8045.0 | 577.0 | 48 | 453 | 000603 |
| 3 | 48453001786 | POLYGON ((-10883185.970 3559253.320, -10883154... | 5283.0 | 70.0 | 48 | 453 | 001786 |
| 4 | 48453001402 | POLYGON ((-10881202.260 3534408.710, -10881206... | 2617.0 | 23.0 | 48 | 453 | 001402 |
Fortunately, you can convert the networkx objects that osmnx focuses on into pandas dataframes, so that both cenpy and osmnx match in their representation. This makes it very easy to work with OSM data alongside of census data.
To convert the OSM data into a pandas dataframe, we must do two things.
First, we need to use the osmnx.graph_to_gdfs to convert the graph to GeoDataFrames, which are like a standard pandas.DataFrame, but with additional geographic information on the shape of each road. The graph_to_gdfs actually produces two dataframes: one full of roads and one full of intersections. We’ll separate the two below:
[6]:
aus_nodes, aus_streets = osmnx.graph_to_gdfs(aus_graph)
Now, the aus_streets dataframe looks like the aus_data dataframe, where each row is a street, and columns contain some information about the street:
[7]:
aus_streets.head()
[7]:
| u | v | key | osmid | highway | oneway | length | geometry | name | lanes | bridge | service | junction | maxspeed | access | ref | width | tunnel | area | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5532286976 | 2022679877 | 0 | 191679752 | service | False | 69.530 | LINESTRING (-97.79634 30.15963, -97.79675 30.1... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | 5532286976 | 5532286980 | 0 | 191679752 | service | False | 17.599 | LINESTRING (-97.79634 30.15963, -97.79632 30.1... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 5532286976 | 5532286980 | 1 | 576925636 | service | False | 126.129 | LINESTRING (-97.79634 30.15963, -97.79593 30.1... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 5532286980 | 5532286976 | 0 | 191679752 | service | False | 17.599 | LINESTRING (-97.79630 30.15948, -97.79632 30.1... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 5532286980 | 5532286976 | 1 | 576925636 | service | False | 126.129 | LINESTRING (-97.79630 30.15948, -97.79611 30.1... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
The last bit of data processing that is needed to make the two datasets fully comport within one another is to set their coordinate reference systems to ensure that they align and can be plotted with webtile backing. The US Census provides geographical data in Web Mercator projection (likely due to the fact that it serves many webmapping applications in the US Government), whereas the Open Streetmap project serves data in raw latitude/longitude by default. For contextily, we’ll need
everything in a Web Mercator projection.
So, to convert data between coordinate reference systems, we can use the to_crs method of GeoDataFrames. This changes the coordinate reference system for the dataframe. To convert one dataframe into the coordinate reference system of another, it’s often enough to provide the coordinate reference of the target dataframe to the to_crs function:
[8]:
aus_streets = aus_streets.to_crs(aus_data.crs)
Now, the two dataframes have the same coordinate reference system:
[9]:
aus_data.crs
[9]:
<Projected CRS: EPSG:3857>
Name: WGS 84 / Pseudo-Mercator
Axis Info [cartesian]:
- E[east]: Easting (metre)
- N[north]: Northing (metre)
Area of Use:
- name: World - 85°S to 85°N
- bounds: (-180.0, -85.06, 180.0, 85.06)
Coordinate Operation:
- name: Popular Visualisation Pseudo-Mercator
- method: Popular Visualisation Pseudo Mercator
Datum: World Geodetic System 1984
- Ellipsoid: WGS 84
- Prime Meridian: Greenwich
[10]:
aus_streets.crs
[10]:
<Projected CRS: EPSG:3857>
Name: WGS 84 / Pseudo-Mercator
Axis Info [cartesian]:
- E[east]: Easting (metre)
- N[north]: Northing (metre)
Area of Use:
- name: World - 85°S to 85°N
- bounds: (-180.0, -85.06, 180.0, 85.06)
Coordinate Operation:
- name: Popular Visualisation Pseudo-Mercator
- method: Popular Visualisation Pseudo Mercator
Datum: World Geodetic System 1984
- Ellipsoid: WGS 84
- Prime Meridian: Greenwich
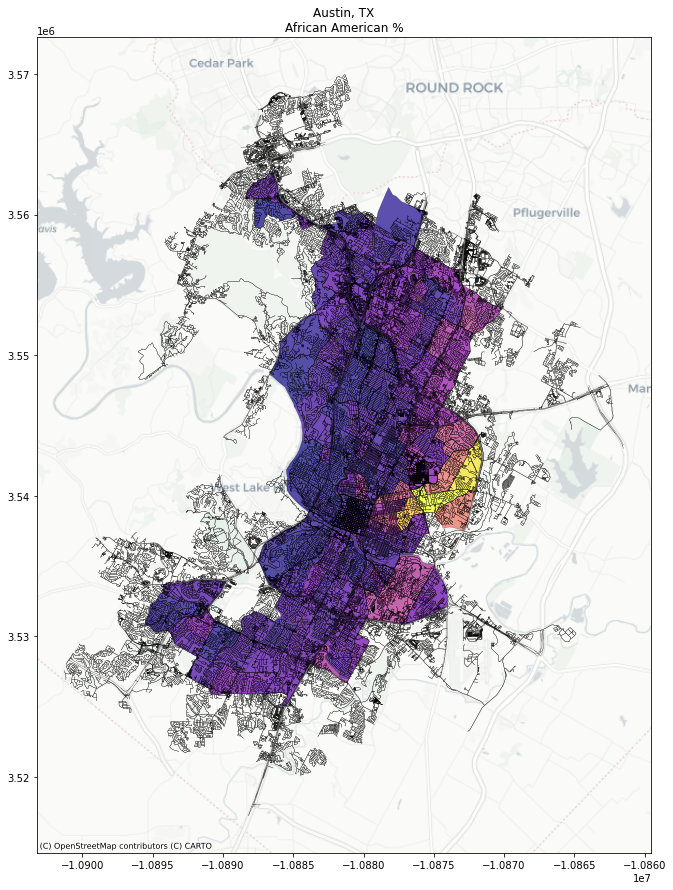
Now, we can make maps using the data, or can conduct analyses using the streets & demographics of Austin, TX. Using contextily.add_basemap, we can also ensure that a nice basemap is added:
[11]:
f,ax = plt.subplots(1,1, figsize=(15,15))
aus_streets.plot(linewidth=.25, ax=ax, color='k')
aus_data.eval('pct_afam = B02001_003E / B02001_001E')\
.plot('pct_afam', cmap='plasma', alpha=.7, ax=ax, linewidth=.25, edgecolor='k')
contextily.add_basemap(ax=ax, url=contextily.providers.CartoDB.Positron)
#ax.axis(aus_streets.total_bounds[[0,2,1,3]])
ax.set_title('Austin, TX\nAfrican American %')
#ax.set_facecolor('k')
[11]:
Text(0.5, 1.0, 'Austin, TX\nAfrican American %')
This means that urban data science in Python has never been easier! So much data is at your fingertips, from_place away. Both packages can be installed from conda-forge, the community-driven package repository in Anaconda, the scientific python distribution. Check out other examples of using `cenpy <https://cenpy-devs.github.io/cenpy>`__, `contextily <https://contextily.readthedocs.io/en/stable>`__ `osmnx <https://osmnx.readthedocs.io/en/stable/>`__ from their respective
websites. And, most importantly, happy hacking!